JDBC Connector
1 Introduction
JDBC Connector is a publishing server plug-in to connect publishing hub to arbitrary SQL databases as content sources. The JdbcConnector acts as a JDBC client to the target database using native queries that can be configured in a configuration file. Query results will be mapped into publishing hub entity data objects.
This document will describe the general functionality, the data flow within the connector, and the various kinds of configurations of the connector.
2 Connector
The JdbcConnector is basically a JDBC client to any database that has a JDBC driver. The JdbcConnector implements the required interface of the publishing server API.
For a better understanding this section starts with a rough overview on processes within publishing server.
2.1 Process chain of priint publishing hub
The following diagram locates the connector within the data flow through the most prominent modules of print suite. Only the typical request directions is shown – the responses on the way back are just symmetrical.
Publishing Server Dataflow
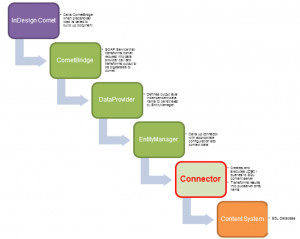
The connector is called upon by the EntityManager module, that reads entity model configurations and calls appropriate commands on the connector to fulfill the queries initiated by the DataProvider manager.
The connector satisfies queries like getRootBuckets for an EntityModel using a Data source that is itself outside the scope of publishing server. The connector implements the required interface from the publishing server API.
The connector reads data from the content system, transforms it to the internal data format of publishing hub and transmits them to the entity manager.
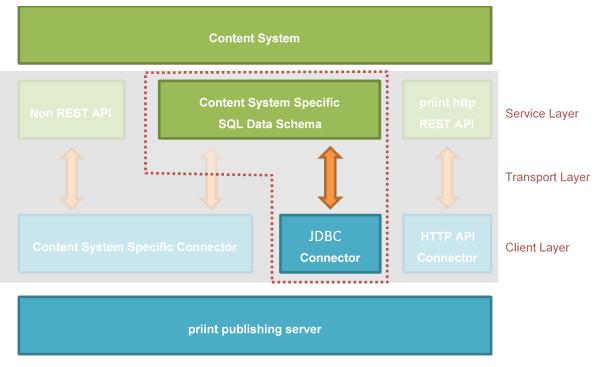
The JdbcConnector uses RDBMS specific SQL statements to retrieve the data.
The connector caches data coming from the content system. Since caching on the connector level is a full responsibility of the JdbcConnector we configure the caching within the connector configuration. Additional caching levels may exist on the side of the RDBMS and also on the side of the Entity Manager within publishing hub. The cache implementation in case of JdbcConnector is based on Ehcache, one of the most wildly used caches for Java VM.
The connector uses a "connector entity identifier" string to build queries for the content system. The semantics of this string are defined within the connector and not controlled by the publishing server. The parsing and interpretation of the string is a task of the connector. Details are given below.
Each connector entity identifier points to a XML configuration element related to the connector instance. The XML configuration is stored within the publishing server and is accessed by the API.
2.2 Implemented Connector Methods
The following list contains all supported Connector methods. The connector currently only supports "read" methods and no methods to write data back into the content system.
Each method supports at least a context and a search string argument. Additional arguments are specific to each method and contain identifiers, group identifiers, target entity identifiers, parent entity identifiers etc.
| Method | Description |
| getRootBuckets | Read top most level of the content system print data hierarchy. |
| getChildBuckets | Read sub-structure elements of a structure elements. |
| getBucketsByIdentifier | Read a structure element by its identifier. |
| getBucketsByGroupIdentifier | Read structure elements by its group identifier. |
| getBuckets | Reads bucket items by its connector entity and filter by search string. |
| getCordedBuckets | Reads many-to-many associated structure elements of a structure elements. |
| getCordsOfBuckets | Reads many-to-many associated structure elements of a structure elements. This returns the associations itself instead of the target elements. |
| getCords | Reads many-to-many associations by its connector entity and filter by search string. |
| getKeyValuesOfBucket | Reads key-value content items of a structure element by identifier of the structure element and connector entity of the key-values. |
| getKeyValuesByIdentifier | Reads a key-value item by its identifier. |
| getKeyValuesByGroupIdentifier | Reads key-value items by its group identifier. |
| getKeyValues | Reads key-value items by its connector entity and filter by search string. |
| getMediaAssetsOfBucket | Reads media asset content items of a structure element by identifier of the structure element and connector entity of the media assets. |
| getMediaAssetsByIdentifier | Reads a media asset item by its identifier. |
| getMediaAssetsByGroupIdentifier | Reads media asset items by its group identifier. |
| getMediaAssets | Reads media asset items by its connector entity and filter by search string. |
| getPricesOfBucket | Reads price content items of a structure element by identifier of the structure element and connector entity of the prices. |
| getPricesByIdentifier | Reads a price item by its identifier. |
| getPricesByGroupIdentifier | Reads price items by its group identifier. |
| getPrices | Reads price items by its connector entity and filter by search string. |
| getTableDataOfBucket | Reads text content items of a structure element by identifier of the structure element and connector entity of the table data items. |
| getTableDataByIdentifier | Reads a table data item by its identifier. |
| getTableDataByGroupIdentifier | Reads table data items by its group identifier. |
| getTableData | Reads table data items by its connector entity and filter by search string. |
| getTextsOfBucket | Reads text content items of a structure element by identifier of the structure element and connector entity of the text items. |
| getTextsByIdentifier | Reads a text item by its identifier. |
| getTextsByGroupIdentifier | Reads text items by its group identifier. |
| getTexts | Reads text items by its connector entity and filter by search string. |
| setBuckets | Inserts or updates bucket items and their metadata. |
| setCords | Inserts or updates bucket items and their content buckets amd metadata. |
| setKeyValues | Inserts or updates bucket items and their sub-keyvalues and metadata. |
| setMediaAssets | Inserts or updates bucket items and their media objects, texts, and metadata. |
| setPrices | Inserts or updates bucket items and their metadata. |
| setTableDatas | Inserts or updates bucket items and their rows, cells and metadata. |
| setTexts | Inserts or updates bucket items and their metadata. |
| deleteBuckets | Deletes bucket items and their children and metadata. |
| deleteCords | Deletes cord items and their content buckets and metadata. |
| deleteKeyValues | Deletes key value items and their sub-keyvalues and metadata. |
| deleteMediaAssets | Deletes media asset items and their mediaObjects, texts and metadata. |
| deletePrices | Deletes price items and their metadata. |
| deleteTableDatas | Deletes table items and their rows, cells and metadata. |
| deleteTexts | Deletes text items and their metadata. |
Some optional methods are not implemented because there is no need for them in JDBC projects. .
Methods other than those listed cannot be used in data providers.
2.3 Process flow within the connector
Processing is done in three phases (getter methods):
| PHASE 1 | Get called by EntityManager, e.g. getRootBuckets |
| The arguments of the call contain context information like resource identifier, language, country, etc. | |
| The arguments of the call also contain the ConnectorEntityIdentifier | |
| ConnectorEntityIdentifier gets parsed into an URI like structure, where the path point to a named configuration element | |
| XML configuration element is read depending on the ConnectorEntityIdentifier | |
| internal request context is built from configuration properties together with context from the EntityManager call | |
| PHASE 2 | Building an SQL query string based on the SQL pattern defined in the configuration element using the request context |
| Reading the SQL query from the cache | |
| If found in cache, proceed with PHASE 3 | |
| If query is not found in cache:Execute the query on the content system (retrieve the actual SQL record set from the database) | |
| On failure:If query fails, transmit a DataSource Exception to EntityManager as expected from the API. | |
| On success:Read record set into internal data structure | |
| Save data structure for this SQL query string into the cache | |
| PHASE 3 | Mapping the record fields to properties of the publishing hub entity item based on values indefined in the configuration element using the request context |
| for each field in a publishing hub entity itemidentify the configuration element defining the mapping | |
| Mapping can be simply a hash map call or a sub query to the database. | |
| Result is a list of publishing hub entity items filled with data from the request to the SQL database |
2.4 Exception Handling
Errors are signaled either as Data Source exceptions or as Connector Exceptions.
They will be logged in the Glassfish server log.
After an error the connector will be open for other requests.
Exception handling can be influenced by the error-mode setting in the configuration. See below.
| Error Type | Description |
| Data Source Exception | When the data source does not deliver any data or otherwise responds with an error.Examples· cannot connect to database· user · credentials do not match· SQL syntax failure |
| Connector Exception | When processing data within the connector fails.Examples· Configuration element is used as ConnectorEntityIdentifier in Entity Model but is missing in configuration XML. |
2.5 Request Context
Processing is organized around a request context.
The request context contains a list of properties that can be used in SQL statements and mapping queries.
The names for the properties are alphanumeric strings that may contain underscores for visual separation of parts. Technically they must match the regular expression "w+ ".
If used in SQL queries as parameter names they must be prefixed with a colon :, like in SELECT * WHERE lang=:context_language. This follows the common JDBC practice.
If used in SQL queries as variable names they must be prefixed with a dollar and embraced in curly brackets, like ${someName}. This follows the Application Server standard for variable resolution.
The request context will be filled from different sources.
- Identifier string or parent identifier string as given in the connector call, e.g. getTextsOfBucket(bucketId).
- Context attributes as part of the method call
- ConnectorEntityIdentifier as part of the method call, esp. query parameter component of the identifier
- Search String as part of the method call
- Base settings of the configuration xml
- Dynamically created properties in query chaining and entity references
Details are described below.
2.5.1 Default properties
These properties cannot be overwritten by properties from searchStr or query parameters of connector entity identifier. These properties will always exist in the context of a query.
| Variable | Description |
| connector_country | Country string related to the connector configuration for countries |
| connector_language | Language string related to the connector configuration for countries |
| connectorEntity_fragment | Fragment part of the connector entity identifier string, i.e. everything after the first "#" character. |
| connectorEntity_identifier | Full connector entity identifier string. |
| connectorEntity_name | Path part of the connector entity identifier string, i.e. everything before the first "?" character. |
| context_assortment | Assortment string from pubserver context. |
| context_country | Country string from pubserver context (ISO two uppercase letter code) |
| context_httpLanguageTag | Language tag to be used as HTTP-Accept Language Header (see RFC 2616) |
| context_language | Language string from pubserver context (ISO three lowercase letter code) |
| context_well | Well string from pubserver context. |
| context_document | (v4.1+ only) document id from pubserver context |
| context_marketName | (v4.1+ only) market name from pubserver context |
| context_publication | (v4.1+ only) publication id from pubserver context |
| context_targetGroup | (v4.1+ only) target group from pubserver context |
| id_separator | Character from XML configuration or default (i.e. a dot “.”) |
| session_comet_language | The language of the comet bridge user, e.g. the language chosen during in the login dialog in InDesign or publishing planner. |
| session_comet_project | The project of the comet bridge user, e.g. the “dataset” chosen during in the login dialog in InDesign or publishing planner. |
| session_comet_region | The region of the comet bridge user, e.g. the region chosen during in the login dialog in InDesign or publishing planner. |
| session_login | The login name of the current user. |
| session_tenant | The tenant (client) of the current user. Defaults to the first client registered, e.g. “Default” or “WerkII”. |
2.5.2 Properties from connector entity
For a Connector Entity Identifier like "products?foo=bar " a Request Context property " foo " with value " bar " will be created. If the same key is used several times the latest assignment will be used, i.e " products foo=bar&fu=Kneipe&fu=Schenke " will produce two properties
- foo => bar
- fu => Schenke
Values from Connector Entity may be overridden by values from Search String.
Keys and values can contain escaped characters as in URL query components. Percent escaping based on UTF-8 is used.
2.5.3 Properties from search string
For a search string like "foo=bar " a Request Context property " foo " with value "bar" will be created. If the same key is used several times the latest assignment will be used, i.e " foo=bar&fu=Kneipe&fu=Schenke " will produce two properties
- foo => bar
- fu =>Schenke
Values from Search String will override values from Connector Entity.
Keys and values can contain escaped characters as in URL query components. Percent escaping based on UTF-8 is used.
2.5.4 Properties from identifier
Queries from entity manager will use an identifier parameter. It is either a bucketIdentifier (getChildrenOfBucket, getTextsOfBucket etc.) or identifier (get TextByIdentifier, etc.) or group identifier (getTextByGroupIdentifier, etc.). All these parameters are subsumed under the notion of “ID”. IDs can either be simple or compound.
Compound IDs contain several ID components separated by a delimiter character. The delimiter character can be configured. Per default it is set to a dot .. If you need ID components that contain dots, you should redefine the delimiter to a save character (see “id-separator” configuration). Do not use whitespace or non-printable characters as delimiter. You may switch to rarely used characters from the full Unicode range.
An ID like “foo.bar” will produce three properties:
- id => foo.bar
- id_1 => fu
- id_2 => bar
You cannot override ID properties by values from Search String or Connector Entity.
You can control the index numbers by the configuration setting “id-index-base”. E.g. <id-index-base>0</id-index-base> would produce “id_0”, “id_1”, etc. Current default for index base is “1”.
2.5.5 Dynamically created properties
Some properties will be added during the processing chain as a result from previous steps.
| Variable | Description |
| entityRef_name | Name of the referred-to entity, i.e. the current entity during reference resolution |
| entityRef_carry | String result of the referring entity, i.e. the input when resolving a entity reference or the "carry-over". |
2.5.6 Properties created for UPSERT and DELETE queries
When a setter or delete method is called with a list of entitydata, then for each item the request context is populated with the field values of the item. A full list of fields and their names is given in the appendix. For the request context the field name will be prefixed by the type of the current item (in lowercase letters).
Example: If modifying a KeyValue the request context will contain fields like "keyvalue_key", "keyvalue_keyLabel", keyvalue_refKeyValueId, etc. Each field is prefixed with the entity class name (in lowercase letters). For a text you have "text_identifier", "text_text" etc.
When processing sub elements of an item like mediaObjects on mediaAssets or metaData on all item types the field prefix will contain the type of the current item and its parent, e.g. mediaasset_mediaobject_url. In case of table data this can get very complex: e.g. tabledata_tabledatarow_tabledatacell_keyvalue_keyLabel will be the request context key of a metadata item of a cell when calling setTableDatas.
2.6 Connector Entity Identifier
The most important element during configuration work will be the Connector Entity Identifier. This syntax of this identifier is specific for the JdbcConnector.
Some examples:
producttext?entityId=product_name&parentEntityId=productopen-source closed-source
The connector entity identifier of the JdbcConnector follows the syntax of URI paths and queries.
<entity-name>?<entity-params>
The entity-name (the path component of the URI) refers to a named configuration element in the JdbcConnector configuration XML described in the next chapter. The example requires an element <entity name="text">…</entity> in the configuration. An entity name should only contain alphanumeric characters and hyphen or dot, i.e. follow the regular expression [w.-]+.
entity-params is an optional list of parameters using the same syntax as query strings in URLs, i.e. pairs are separated by "&" and key are separated from values by "&". Non ASCII characters or special characters like "&", "=", "#" must be percent escaped like "%20" for the space character.
The parameters can be used to easily reuse a named entity for different queries. They can be used when building the SQL queries or when selecting columns from result sets.
An identifier can point to more than one entity configuration element within one connector entity identifier. Technically the identifier is a list of URIs separated by whitespace.
An example: open-source closed-source
This means that to retrieve entity data for this entity the connector will combine the results from two queries internal to the connector (open-source and closed-source). The sequence if items will reflect the sequence in the connector entity identifier.
2.7 SQL Processing
SQL strings are stored as templates in the connector configuration file.
Processing of SQL queries is done via JDBC. SQL statements must use the SQL dialect of the target database.
During a request, they are processing in the following steps.
| Step | Description |
| Variable Resolution | Before executing a statement on a request the variables placeholders in the string will be replaced by values from the request context. If a query is SELECT ${colname} FROM mytable and the connector entity identifier contained "t ext?colname=mycol17 " the effective SQL will be " SELECT mycol17 FROM mytable ". For security reasons variable are only allowed to contain alphanumeric characters. |
| Parameter List Creation | In a second step, all parameters (i.e. strings prefixed by a colon) are identified and a parameter list is created. |
| SQL Execution | The query is the executed using the parameter list created in the step before. All CLOB objects will be retrieved immediately. Each record will be accessible as associative array for the following processing. |
3 Installation
The connector is delivered as a "jar" file:
JdbcConnector.4.4.0.XXXX.jar
The connector jar is deployed via any of the standard Glassfish deployments procedures.
The recommended way is to deploy via the "autodeploy" hot folder. The autodeploy folder will be respected by the pubserver update process. For any other deployment procedure, a redeployment of the connector needs to be done after a pubserver update. This is to ensure the correct sequence of deploying.
After the basic installation of the JdbcConnector, it will be visible in the ison configuration tool, but it still needs some configuration. See configuration section in this document.
4 Configuration
4.1 Configuration File
The configuration of the JdbcConnector instance is done by using a Publishing Server Plugin Configuration file containing an com.priint.pubserver.connector.db.JdbcConnector/<TENANT>/default. Of course, TENANT must be replaced by the actual tenant in the system.
If the config folder or file do not exist, create this folder and file using ison:
com.priint.pubserver.connector.db.JdbcConnector/<TENANT>/default/default.xml.
The file name "default.xml" is okay if you are working with one instance only.
The screenshot shows a configuration for the fictional connector instance "kontoso" on a "Default" tenant.
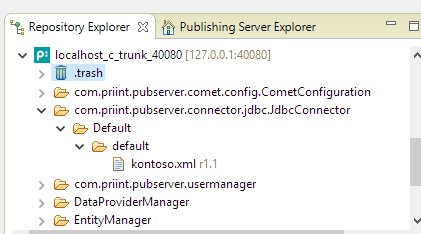
4.1.1 Using the "default" instance
The easiest way to start with a configuration is to set up the "default" instance. The configuration of the default instance can be done within the custom element of the top level PluginConfig element of a configuration.
This is recommended for all projects, where not more than one instance of the connector will be needed. And even if you need more than one instance, they can co-exist with the default instance.
<con:PluginConfig xmlns:con="com.priint.pubserver.config.manager/20130620">
<con:name>default.xml</con:name>
<con:type>ContentConnector</con:type>
<con:custom>
<jdbc-connector version="1.0">
<!-- content goes here -->
</jdbc-connector>
</con:custom>
</con:PluginConfig>
4.1.2 Using named instances
Named instances are needed if you have different entity models or different tenants using the connector. In this case, it is wise to use a named instance for each individual model. The best name for an instance is just the entity model name.
Named instances are set within the instances element of the top level PluginConfig element. Each instance has an entry element with a key (i.e. the instance name) as a wrapper for an inner PluginConfig element.
Named instances will be listed in ison, if you edit the entity model. You can just select the correct one from the drop-down menu.
Named instances can be used together with a default instance.
It is recommended to create separate config files for each instance and use the instance name (
<con:PluginConfig xmlns:con="com.priint.pubserver.config.manager/20130620">
<con:name>kontoso.xml</con:name>
<con:type>ContentConnector</con:type>
<con:instances>
<con:entry key="kontoso">
<con:PluginConfig>
<con:name>kontoso</con:name>
<con:type>ContentConnector</con:type>
<con:custom>
<jdbc-connector version="1.0">
<!-- content goes here -->
</jdbc-connector>
</con:custom>
</con:PluginConfig>
</con:entry>
<con:entry>
...
</con:entry>
</con:instances>
</con:PluginConfig>
4.1.3 Inheritance between Instances
You can base an instance on another already existing instance. Properties with no explicit definition in your new instance will be taken from the base instance. E.g. the base instance has some entities or some named mappings that you want to reuse, you can do this using the "based-on" attribute on the top level "jdbc-connector" configuration element.
In the Example the instance "kontoso2" is based on "kontoso". The "kontoso" instance must be defined either within the current configuration file or also can be taken from another configuration file within the JdbcConnector config folder, or it can be taken from some build-in configuration.
<con:PluginConfig xmlns:con="com.priint.pubserver.config.manager/20130620">
<con:name>kontoso2.xml</con:name>
<con:type>ContentConnector</con:type>
<con:instances>
<con:entry key="kontoso2">
<con:PluginConfig>
<con:name>kontoso2</con:name>
<con:type>ContentConnector</con:type>
<con:custom>
<jdbc-connector version="1.0" based-on="kontoso">
<!-- content goes here -->
</jdbc-connector>
</con:custom>
</con:PluginConfig>
</con:entry>
</con:instances>
</con:PluginConfig>
4.2 JDBC Configuration
The "jdbc-connector" element in the configuration defines, how the connector instance should behave. Many different configurations are possible to suite different project scenarios.
Some elements that are direct children of the
Parent Elements:
| Node (xpath) | Required | Named | Description |
| @based-on | No | n.a. | Relation to another jdbc-connector configuration instance. The value refers to a /PluginConfig/instances/entry/@key within the same or another config file. An empty string denotes the “default” instance, i.e. the root level custom element in the plugin configuration. Instance names embraced in brackets denote “built-in” instances, that are part of the jar file and cannot be changed. |
| @version | No | n.a. | Version of the jdbc-connector configuration type. Currently only one version of configurations exists.Default: "1.0" |
| /connection | No | Yes | Defines the database connection as configured as JDBC resource in the application server.There can be more than one connection elements. Only the first one will be used as default connection for the configuration. Other can be referenced by "based-on" attribute in sub elements. |
| /entities | Yes | No | The entities element is a wrapper for a list of single entity definitions. |
| /entities/entity | Yes | Yes | Each entity definition has a name. This name is the first part of the connector entity identifier as set in the entity model in ison. This name related the entity model with the connector configuration. |
| /cache | No | Yes | Defines the general caching strategy.There can be more than one cache element. The first element is used as default. Typically, it has no name. Other cache elements can only be used by reference. |
| /mappings | No | Yes | Optional named mappings. Each mappings element contains a list of mappings from a SQL column name to a property of an entity data item within publishing hub. |
| /countries | No | No | The countries element is a wrapper for a list of single country definitions. Country definitions are optional. |
| /countries/country | No | No | Each country element defines a name-value pair defining the mapping between a country value used in the content system and the corresponding value used within publishing hub. |
| /languages | No | No | The languages element is a wrapper for a list of single language definitions. Language definitions are optional. |
| /languages/language | No | No | Each language element defines a name-value pair defining the mapping between a language value used in the content system and the corresponding value used within publishing hub. |
| /error-mode | No | No | Specifies the handling of exceptions. Default is " abort" (the typical behavior of other connectors), i.e. let the EntityManager handle the exception. EntityManager may only write some log information not available to the end user. "ignore" will swallow exceptions, "inform" will generate special entity data items designating the error. "inform" items will be visible to the end user.Default is: abort |
| /default-query-type | No | No | Controls how queries by identifier or by group-identifier are handled if there is no explicit query definition for them. default-query-type defaults to " children". This means that, e.g. if no <query for="identifier"/> is found within the entity, the last of the <query for="children"/> will be used. |
| /encode-identifiers | No | No | Control whether forbidden characters in identifiers are replaced by their numerical entities, e.g. "" by "&92;. Replacing is reversed when using the identifier in SQL. |
| /params | No | No | The params element is a wrapper for a list of arbitrary parameter settings that can be used in the request context. |
| /params/param | Each param element defines a name-value pair. It is added to the request context of each query. | ||
| mappings | No | Yes | Optional named mappings. Each mappings Element contains a list of mappings from a XML or JSON field to a property of an entity data item within publishing hub. |
| /id-separator | No | No | Delimiter for splitting identifiers coming from entity manager into parts available via RequestContext. Default is the dot ".". If you need dots in identifiers itself, you should change the id-separator to some other value. E.g. "|", ",", ":" or even "‖". If id-separator is enclosed in "/" it is expected to be a regular expression. E.g. "/[|:]/" will split at every "|" and every ":". Construction of compound IDs should be done in field definitions. Parts of the identifiers will be available via RequestContest as "id", "id_1", "id_2", "id_3" etc. where "id" contains the full compound. This can also be used in url patterns and xpath as property "id_separator". But only if it is not a regex.Note: “#” is not allowed in id separators because it reserved as comet StringID separator . |
| /id-index-base | No | No | (either 1 or 0) (Default = 1) Controls whether splitting for id's will create properties starting with "id_0", "id_1" etc. or "id_1", "id_2" etc. |
4.3 Connection Configuration
Defines the database connection as configured as JDBC resource in the application server.
Parent Elements: jdbc-connector, entity, query
| Node (xpath) | Required | Description |
| @based-on | No | Only on sub-level connections. Relation to another connection within the same configuration instance. The value refers to a jdbc-connector/connection/@name attribute. |
| @name | No | Only on top-level connections. Name for the current connection. To be used in references via "based-on". |
| /jndi-name | No | JNDI resource name in application server, e.g. jdbc/sampledb1. JNDI names are defined via application server administration. It is called JDBC resource name in Glassfish. See appendix for an example.Default is "jdbc/JdbcConnector" |
| /logging | No | Enable/disable logging the effective SQL queries and return values from the database server into the server logfile. Logging should only be activated during debugging. It writes a lot of data into the log file and slows down performance.Default: false |
4.4 Cache Configuration
If a cache configuration is needed during the processing of a query it will be search for bottom-up through the configuration file. If there is no explicit definition of cache for a query or the parent entity, then the first top level cache element will be used.
Parent Elements: jdbc-connector, entity, query
| Node (xpath) | Required | Description |
| @based-on | No | Only on sub-level caches. Relation to another cache within the same configuration instance. The value refers to a jdbc-connector/cache/@name attribute. |
| @name | No | Only on top-level caches. Name for the current cache. To be used in references via "based-on". |
| /external-name | No | Name to reference a configuration element of the actual cache implementation, e.g. Ehcache. |
| /max-duration | No | Duration in seconds that an item will survive in the cache until it expires.Default is: 0 (no caching) |
4.5 Entity Configuration
Parent Elements: entities
| Node (xpath) | Required | Description |
| @name | No | Name for the current entity. To be used as path component in the connector entity identifier of the publishing hub. |
| /cache | No | Can be used to override the cache for this entity. If not set the default cache from the parent element will be used. |
| /connection | No | Can be used to override the connection for this entity. If not set the default connection from the parent element will be used. |
| /query | No | If no query is defined the default SQL and mappings will be used. |
| /mappings | No | Default db-column to pubserver-field mappings. These mappings will be used if the query does not define its own mappings.If not defined, the default mapping will expect db-columns to have the same name as pubserver-fields. |
4.6 Query Configuration
Parent Elements: entity
| Node (xpath) | Required | Description |
| @for | No | Query type. This configuration element can be used in either getItemsByIdentifier or getitemsByGroupIdentifier or getChildrenOfItem queries.Default is "children" because child queries are the most prominent one. In many cases "byIdentifier" queries are just the same except for an additional where clause. Clever designed SQL queries can handle both cases, so that you only need one SQL query altogether for a connector entity. See examples. |
| @input-type | No | Only used in query chaining. Input-type is the result type of the preceding query, either "record", "recordlist", or "none" (default). |
| /cache | No | Can be used to override the cache for this entity. If not set the default cache from the parent element will be used. |
| /connection | No | Can be used to override the connection for this entity. If not set the default connection from the parent element will be used. |
| /mappings | No | db-column to pubserver-field mappings.If not given the mappings from the parent entity definition will be used. |
| /command | No | Command for this query. Typically this is the SQL statement to be executed. You may use variables and parameters in SQL statements. See special section on this below.In SimpleDB connector this was named <sql/>. |
| /command/@type | No | (default is "sql") Currently supported values are "sql" and "pubserver". The connector may support other command types as well. In the examples section you find a demo configuration showing how to call the parameter interpreter of publishing server. |
4.7 Mappings Configuration
Parent Elements: jdbc-connector, entity
| Node (xpath) | Required | Description |
| @based-on | No | Only on sub-level mappings. Relation to another mappings element within the same configuration instance. The value refers to a jdbc-connector/mappings/@name attribute. All <mapping/> elements in the referred-to mappings will be copied into the current mappings element if not already defined. |
| @name | No | Only on top-level mappings. Name for the current mapping. To be used in references via "based-on". |
| /mapping | Yes | List of <mapping/> elements. |
4.8 Mapping Configuration
Parent Elements: mappings
The mapping configuration defines which result columns of a record will be used for which field in a publishing server entity data item.
An explicit mapping is only needed if the column names in the record set deviate from the entity data field names. Per default the connector expects that the result columns already have the same names as the entity data fields.
A list of supported entity data item fields is given in the appendix.
| Node (xpath) | Required | Description |
| @for | Yes | Name of the entity data field. E.g. "identifier" or "label" or "metaData" in buckets. |
| /field-path | Yes | Name of the record column in the result set, that should be used in filling the entity data field. Names prefixed with a colon ":" have a special meaning: They will be resolved from the request context.Note: This field has the name "select" in old SimpleDB and EasyRest configurations. |
| /transform | No | A transformation rule or format string to translate strings coming from the database into pubserver format. This can for a DateTime format string for Date objects, a simple sprintf format string for String objects or the name of a static Java method that should be used for translation.See examples in the appendix. |
Recommendation: For literal fields (string, number, date) do not specify an explicit mapping. Instead use appropriate column alias in your SQL SELECT statement. For object fields like metaData, mediaObjects, or refKeyValue you will always need an explicit configuration.
Explicit Configuration Example
<query for="children">
<command>
SELECT
pk, title
FROM someTable WHERE ... ORDER BY ...
</command>
<mappings>
<mapping for="identifier"><field-path>pk</field-path></mapping>
<mapping for="label"><field-path>title</field-path></mapping>
</mappings>
</query>
Implicit Configuration Example (names "identifier" and "label" will automatically be mapped)
<query for="children">
<command>
SELECT
pk AS identifier,
title AS label
FROM someTable WHERE ... ORDER BY ...
</command>
</query>
4.9 Error Mode
Parent Elements: jdbc-connector
The error-mode element controls how errors will be displayed.
| Value | Description |
| abort | If an exception is caught it will be handed over to the calling method i.e. most exception will be handled by EntityManager. |
| ignore | If an exception is caught it will not be handed over to the calling method but simply swallowed. Output will be NULL or an empty list depending on the response type. |
| inform | If an exception is caught it will not be handed over to the calling method but a special error bucket (or text etc.) will created and returned instead.Error will be visible to the user within ison or comet desktop. |
4.10 Language and Country Codes
Parent Elements: jdbc-connector
Mapping between pubserver language and country codes and content system specific codes.
Publishing server manages languages inISO_639_3_Alpha3 format (e.g. "eng" for English and "deu" for German). Countries are managed in ISO_3166_1_Alpha2 format (e.g. "GB" for United Kingdom and "DE" for German). If the database uses another format, then the connector must translate the codes from and to publishing server. You must then define the mapping in the configuration.
The following snippet defines such a language mapping in the configuration file. The name attribute contains the internal pubserver code, the value contains the external (database) code.
<languages>
<language name="deu" value="de" />
<language name="eng" value="en" />
</languages>
If the connector finds no mapping for a code, it assumes that the database already uses ISO_639_3_Alpha3 for languages.
The following snippet defines a country mapping in the configuration file.
<countries>
<country name="DE" value="276" />
<country name="GB" value="826" />
</countries>
If the connector finds no mapping for a code, it assumes that the database already uses ISO_3166_1_Alpha2 for countries.
Mismatches of languages and countries may lead to IllegalArgumentException in Java saying "Language or country code not supported …"
4.11 Global Parameters
Parent Elements: jdbc-connector
Add global parameters to extend the query context.
<params>
<param name="p1" value="peh-eins" />
<param name="p2" value="{session_tenant}">
<default>uups-no-tenant</default>
</param>
</params>
You can just define string literals as constants for later use in SQL statements. You can use other parameters from the context in the definition. You can also define a default for such a parameter. In the example a default for the situation that the "session_tenant" field is not filled, for whatever reason.
4.12 Query Input Attribute
Parent Elements: query
In query chaining subsequent queries need to specify an interpretation rule for their input.
| Value | Description |
| record | Input represents exactly one database record. A sub query will be executed retrieving a list of records. The resulting record list will be the input for the next processing step (another query or a mapping). |
| record-list | Input represents a list of database records. For each record a sub query will be executed retrieving a single record. The resulting record will replace the original record as the input for the next processing step (another query or a mapping). |
4.13 Query Type Attribute
The error-mode element controls how errors will be displayed.
| Value | Description |
| children | Handles entity manager queries of type "get child or content nodes for a bucket". |
| identifier | Handles entity manager queries of type "get entity data item by identifier". |
| group | Handles entity manager queries of type "get entity data item by group identifier". |
| upsert | Handles entity manager queries of type "set entity data items". |
| delete | Handles entity manager queries of type "delete entity data items". |
| search | Handles entity manager queries of type "get entity data" where the only argument is a search string. |
5 Variables and Parameters in SQL Queries
You can use variables and parameters in SQL statements.
Consider an SQL query like the following
SELECT c.id AS identifier, c.${column} as text
FROM examples c
WHERE c.id = :id
It contains two kinds of placeholders:
SQL Parameter Parameters are starting with a colon, for example :id. They get replaced during SQL execution by the corresponding field values. To escape the starting colon, please start with a doubled colon, i.e. ::id. This will be replaced by the string literal ":id".
SQL Variable Variables are starting with ${ and ending on }, for example ${column}. Variables are replaced by values from the request context before the execution of the parametrized query. Only alphanumeric chars and "_" are allowed in variable names and variable values. Other characters will be replaced by "_", to sanitize for SQL injections. To escape the starting $ character, please start with a doubled dollar, i.e. $${column}. This will be replaced by the string literal ${column}.
Note: There is no SQL syntax analysis involved in placeholder identification. It is just a string replacement. A … WHERE name = ‘xy :z’ will be replaced by … WHERE name = ‘xy ?’ and adding a parameter "z" to the list of parameters for the execution. So, you must escape each occurrence of a colon followed by a word character that should be kept in the string. Likewise with variables matching the regular expression \\$\\{\\w+\\}.
6 Entity Definition in ison
In ison (Entity Explorer) for each entity you must specify the following properties.
| Name | Description |
| Connector | com.priint.pubserver.connector.db.JdbcConnector |
| Instance | Name of the configuration section in the connector.xml, that should be used in queries. |
| Identifier | Part preceding the question markName to the <entity/> element, that should be used in the query.Part following the question markFree definable key-value pairs. Syntax is as URLs. These pairs will be added to the request context when the connector evaluates requests in runtime. In the example below only one pair is in use: „column" defines the name of a column in the database record set returned. |
The screenshot below shows how the JdbcConnector isused in an entity model in ison. In this case it is a text entity for the "yc-demo".
Example
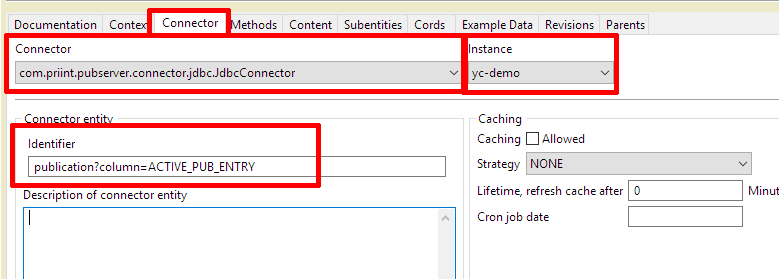
This can be read the following way:
To retrieve the entity „publication", JdbcConnector should be used with the configuration instance „yc-demo". In the configuration the connector should look for a connector entity named „publication. The query defined at that location should be executed. From the result set the column „ACTIVE_PUB_ENTRY" should be returned as "text" value of a text entity.
JdbcConnector will only show up in the connector drop down list if has been deployed into Glassfish. Directly after the such deployment you may have to restart Eclipse to make the connector visible.
The list of instances is taken from the configuration file for the JdbcConnector.
7 Appendix
7.1 JDBC Resources
A JDBC resource is a named reference to a JDBC connection pool. It can be easily created via Glassfish web administration UI. To create a connection pool please read the Glassfish documentation and contact your database admin. Details are specific to the RDBMS at hand.
The name of the resource must start with „jdbc/", e.g. „jdbc/konsoso_prod".
The resource name is the key that must be used in the connector configuration files. It is used as "jndi name" element of the connection element.
<jdbc-connector version="1.0">
<connection>
<jndi-name>jdbc/konsoso_prod</jndi-name>
</connection>
</jdbc-connector>
When setting up new resources please:
- Check if database pool can be pinged in Glassfish
- Check if jndiName element in configuration matches the jdbc resource name in Glassfish Otherwise you get an NameNotFoundException in the logfile
If you did not provide a jndiName in the config, the connector searches for "jdbc/JdbcConnector".
7.2 Entity data fields
Mappings can use the following fields of publishing server entity data types. The "for" attribute of a mapping definition must exactly match the names given in the list.
| Entity Type | Field Name : Type |
| (all types) |
|
| (all types but only if "versioning" attribute is set to "true" on mappings element) |
|
| Bucket |
|
| Cord |
|
| KeyValue |
|
| MediaAsset |
|
| MediaObject |
|
| Price |
|
| TableData |
|
| TableDataCell |
|
| TableDataRow |
|
| Text |
|
String fields are directly mapped without any conversion.
Integer fields must either be of integer datatype in the database output or must contain a string that is parsable as an integer.
Date fields must either be of integer type (msec since 1970) or must be a string. If the value is a string you must provide a format pattern, so that the string can be parsed into a Java Date objects. Format pattern follow the rules of Java SimpleDateFormat. See http://docs.oracle.com/javase/6/docs/api/java/text/SimpleDateFormat.html .
List fields are used for sub-mappings. Sub-mappings return a list of EntityData object, likeBucket, Text, MediaObject, etc).
There also exist some individual EntityData fields, like refKeyValue in KeyValues, that are used in sub-mappings to single EntityData objects, like Bucket, Text, MediaObject, etc).
7.3 Ehcache Configuration
The JdbcConnector uses Ehcache for caching request results.
Per default a configuration for Ehcache is used that is build-in into the connector. You can override this build-in configuration by your own. Place a file named "JdbcConnector.ehcache.xml" into the glassfish domain config folder.
Here is an example:
Location: C:\devstack\Glassfish\glassfish3\glassfish\domains\pubserver\config\JdbcConnector.ehcache.xml
<ehcache name="JdbcConnector" dynamicConfig="true" updateCheck="false">
<defaultCache eternal="false" timeToIdleSeconds="0" timeToLiveSeconds="120" overflowToDisk="false" maxEntriesLocalHeap="1000">
<persistence strategy="none" />
<sizeOfPolicy maxDepth="10" maxDepthExceededBehavior="continue" />
</defaultCache>
<cache name="product" eternal="false" timeToIdleSeconds="0" timeToLiveSeconds="600" overflowToDisk="false" maxEntriesLocalHeap="100" >
<persistence strategy="none" />
<sizeOfPolicy maxDepth="10" maxDepthExceededBehavior="continue" />
</cache>
</ehcache>
You can specify named caches. To use a named cache from the Ehcache configuration you have to specify the external-name element for a cache. Products will use a special cache with a maximum of 100 entries expiring after 600 seconds.
Here is an example:
<entity name="product">
...
<cache external-name=" product" />
...
</entity>
8 Example Configurations
SQL statements are hypothetical. It is just to show how is works in principle.
SQL dialect used in the examples is MYSQL.
8.1 Full example with explanations
This simple example uses one database view for all data - buckets, and texts in this case.
Note: There are two text entities defined - „text" and „singletext". These are alternative options. „text" reads all columns from the database view."singletext" reads only one column plus the identifier. In both cases you must specify the exact column to use for the main data field In the entity model. In most cases "text" will be the better approach if used with caching.
<jdbc-connector version="1.0">
<connection>
<jndi-name>jdbc/kontoso-q</jndi-name>
<logging>true</logging>
</connection>
<cache>
<max-duration>10</max-duration>
</cache>
<error-mode>inform</error-mode>
<entities>
jndi-name = jdbc/kontoso-q
The JDBC resource "jdbc/kontoso-q" defined in Glassfish administration will be used for all queries. In the JDBC resource server host, port, database, user, password etc. are specified.
logging = true
Native SQL queries, parameter values and responses will be written to log file.
max-duration = 10
Results of SQL Queries will be cached for 10 seconds.
error-mode = inform
If errors occur, they will be returned as Bucket or Text items to the client (ison or comet). Errors like typos in field names of a databaseview can be detected easily.
<entity name="bucket">
<command>
SELECT c.REC_NO AS "identifier", c.REC_TITLE AS "label"
FROM PIM_KONTOSO_VIEW c
WHERE :id IS NULL OR :id = c.REC_NO
</command>
</entity>
Entity „bucket"
The result fields "identifier" and "label"match the names of the entity data fields. That iswhy we need no explicit mappings. By the clever WHERE statement this query can be used for querying the main list (root buckets) as well as querying elements by identifier.
<entity name="text">
<command>
SELECT *
FROM PIM_KONTOSO_VIEW
WHERE :id = c.REC_NO
</command>
<mappings>
<mapping for="identifier">
<field-path>REC_NO</field-path>
</mapping>
<mapping for="text">
<field-path>:column</field-path>
</mapping>
</mappings>
</entity>
Entity „text"
All columns for all text entities ofbucket will be read in a single step. This is done by a simple „SELECT * FROM viewname". The name of the result fields a defined in the database view. They have to be mapped to the publishing server property names explicitly.
The „identifier" property of publishing server should be read from the the REC_NO column. The SQL column name for the text" property will be read from the „:column" variable. The „column" variable has to be defined in the Connector Entity Identifier via ison entity explorer. The connector entity identifier for the view column „MY_FIRST_COL" would be „text?column=MY_FIRST_COL".
<entity name="singletext">
<command>
SELECT c.REC_NO AS "identifier", c.${column} as "text"
FROM PIM_KONTOSO_VIEW c
WHERE :id = c.REC_NO
</command>
</entity>
Entity „singletext"
The entity „singletext" is an alternative to the „text" entity. Here field values will be queryied one by one if needed. The target field name will be written into the SQL statement from a variable. Syntax convention for this is: ${varname}, where the value will be taken from the connector identifier parameter string.
</entities>
</jdbc-connector>
8.2 Buckets
Variant 1 - child buckets if parent bucket id is known All mappings are done within the SQL SELECT statement. No other mappings needed here unless you need metaData (see example for "Meta Data or SubKeyValues").
<entity name="bucket">
<query for="children">
<command>
SELECT pk AS identifier, title AS label
FROM my_bucket_view
WHERE parent_id=:id
ORDER BY seq
</command>
</query>
<query for="identifier">
<command>
SELECT pk AS identifier, title AS label
FROM my_bucket_view
WHERE pk=:id
</command>
</query>
</entity>
Variant 2 - reading child and root buckets by the same statement
You will need some kind of if-then-else construct in your SQL that checks if the parent identifier in ":id" is null.
All mappings are done within the SQL SELECT statement. No other mappings needed here unless you need metaData (see example for "Meta Data or SubKeyValues").
<entity name="bucket">
<query for="children">
<command>
SELECT pk AS identifier, title AS label
FROM my_bucket_view
WHERE (NOT ISNULL(:id) AND parent_id=:id) or (ISNULL(:id) AND ISNULL(parent_id))
ORDER BY seq
</command>
</query>
<query for="identifier">
<command>
SELECT pk AS identifier, title AS label
FROM my_bucket_view
WHERE pk=:id
</command>
</query>
</entity>
8.3 Mapping Context, Languages, etc.
We use a text entity as ab example here.
We have two kinds of mapping: from pubserver context to SQL and back from SQL to pubserver context.
In this case the "ctry" column in database is directly mapped to the pubserver context field for country. The column must contain uppercase ISO-two-letter values for country, like "DE" or "JP".
We have a translation for the language values as can be seen from the use of "connector_language" instead of "context_language". The column must contain lowercase ISO-three-letter values for languages like "deu" or "fra". For this we have to add a languages mapping in the configuration.
Other context fields are mapped the same way, context_well, context_assortment, etc.
<xml>
<languages>
<language value="de" name="deu" />
<language value="fr" name="fra" />
</languages>
<entities>
<entity name="text">
<query for="children">
<command>
SELECT pk AS identifier, value AS text, lang AS connector_language, ctry AS context_country
FROM my_text_view
WHERE parent_pk = :id
AND (lang=:connector_language OR ISNULL(:connector_language)
AND (ctry=:context_country OR ISNULL(:context_country)
ORDER BY seq
</command>
</query>
<query for="identifier">
<command>
SELECT pk AS identifier, value AS text, lang AS connector_language, ctry AS context_country
FROM my_text_view
WHERE pk=:id
</command>
</query>
</entity>
</entities>
</xml>
8.4 Media Assets
Variant 1 - more than one media object - retrieved by second query
<xml>
<entity name="mediaAsset_v1">
<query for="children">
<command>
SELECT identifier, label, context_country, context_language
FROM my_media_view
WHERE parent_identifier=:id
ORDER BY seq
</command>
</query>
<query for="identifier">
<command>
SELECT identifier, label, context_country, context_language
FROM my_media_view
WHERE identifier=:id
ORDER BY seq
</command>
</query>
<mappings>
<mapping for="mediaObjects" entity-ref="mediaObject_v1">
<field-path>identifier</field-path>
</mapping>
</mappings>
</entity>
<entity name="mediaObject_v1">
<query for="children">
<command>
SELECT identifier, filename, url
FROM my_media_view
WHERE parent_identifier=:id
ORDER BY seq
</command>
</query>
</entity>
</xml>
Variant 2 - one media object - all retrieved in a single query using JOIN
<entity name="mediaAsset_v2">
<query for="children">
<command>
SELECT m1.id as identifier, m1.name as label, m2.path as filename
FROM my_media_view m1
LEFT JOIN my_media_object_view m2 ON m2.my_media_id = m1.id
WHERE m1.parent_identifier=:id
ORDER BY seq
</command>
</query>
<mappings>
<mapping for="mediaObjects" />
</mappings>
</entity>
8.5 Meta Data or SubKeyValues
This is similar to all other fields containing lists of entity data items.
In the example we have a media asset and want to fill the metaData field. Working with keyValue.subKeyValues or mediaAsset.mediaObjects is just the same.
<xml>
<entity name="mediaAsset_withMetaData">
<query for="children">
<command>
SELECT identifier, label, context_country, context_language
FROM my_media_view
WHERE parent_identifier=:id
ORDER BY seq
</command>
</query>
<query for="identifier">
<command>
SELECT identifier, label, context_country, context_language, object_id
FROM my_media_view
WHERE identifier=:id
ORDER BY seq
</command>
</query>
<mappings>
<mapping for="metaData" entity-ref="metaDataRef">
<field-path>identifier</field-path>
</mapping>
<mapping for="mediaObjects" />
</mappings>
</entity>
<entity name="metaDataRef">
<query for="children">
<command>
SELECT m.id AS identifier, m.name AS key, m.content AS value
FROM my_metadata_view AS m
WHERE m.obj_id=:id
ORDER BY seq
</command>
</query>
</entity>
</xml>
8.6 RefKeyValue
This is similar to reading subKeyValues. The only difference is, that only the first record from the entity-ref query will be used.
<xml>
<entity name="keyValue">
<query for="children">
<command>
SELECT identifier, key, keyLabel, value
FROM my_attributes_view
WHERE parent_id=:id
ORDER BY seq
</command>
</query>
<query for="identifier">
<command>
SELECT identifier, key, keyLabel, value
FROM my_attributes_view
WHERE identifier=:id
</command>
</query>
<mappings>
<mapping for="refKeyValue" entity-ref="refKeyValue">
<field-path>identifier</field-path>
</mapping>
</mappings>
</entity>
<entity name="refKeyValue">
<query for="children">
<command>
SELECT identifier, key, keyLabel, value
FROM my_global_attributes_view AS m
WHERE m.identifier=:id
LIMIT 1
</command>
</query>
</entity>
</xml>
8.7 Calling parameter interpreter instead of SQL
This example show how to call the publishing server parameter parser from the connector. This can be useful if some of your data are not stored in a database but are retrieved by other means.
<entity name="Facet_VR_Group_Hierarchy">
<query for="children">
<command type="pubserver"><![CDATA[
plugin(globalName='com.priint.pubserver.plugin.FacetPlugin',methodName='getVRFacetRootBuckets')[<requestContext>,<dataSource>]
]]></command>
</query>
</entity>
The input of the method are arguments embraced in angular brackets. It can consist of:
- any simple field in the request context, like e.g.
<context_language>or<id_1>, ... - it can be the whole request context as a
HashMap<String, Object>and named<requestContext> - it can be an instance of the JDBC data source object configured in the connection and named
<dataSource>. - Of course it can also be a string literal, like 'Hello priint'.
The output of the method MUST be a List<Map<String, Object>> mimicking a result set of a database query. To map the output to e.g. a bucket, the list items (the maps) MUST contain keys like "identifier" and "label". Other entity data types are built the same way.
8.8 Data modifying queries
In some scenarios where JdbcConnector is used the necessity to manipulate records in the database arises. New records must be added, existing ones updated or deleted.
Two special query types (for="upsert" and for="delete") can be used for this.
While writing data back can be done it is sometimes hard to configure. This depends mainly on two things:
- the structure of the target database
- if you only want to insert, update or delete simple recordsor if you need to handle subordinate data in referenced tables as well.
The connector will send a series of commands in one transaction.
To create the SQL statements you can use the same context variables as for select statements. The connector will populate the request context before executing the call with the entitydata properties.
If modifiying a KeyValue the request context will contain fields like "keyvalue_key", "keyvalue_keyLabel", keyvalu_refKeyValueId, etc. Each field is prefixed with the entity class name (in lowercase letters). For a text you have "text_identifier", "text_text" etc.
The context values will always be in "context_language" and "connector_language", etc.
We will do the documentation by a full example using text data.
All other data types can be configured in analogy.
8.8.1 Configuration Example: Simple Text Data
Suppose we have to store new text data associated with a bucket. We also want to update or delete later.
The database table for texts is defined as such:
\-- MYSQL example for a simple table containing text data
CREATE TABLE textdata (
id INT AUTO\_INCREMENT PRIMARY KEY,
key VARCHAR(30),
pid INT,
ctry VARCHAR(2),
lang VARCHAR(2),
value VARCHAR(4048)
)
Important is to state the additional condition that the parent identifiers stored in "pid" must also be of integer type. So bucket identifiers for these texts are expected to be Strings containing integer values.
Second important information is that identifiers in the table are generated automatically by the database. The business methods in publishing server using the connector setter methods, should not create identifiers on there own.
The connector will typically be called from EntityManager with methods like
- setTexts(
List<Text>, String searchStr) - deleteTexts(
List<Text>)
These methods work on a list of entitydata items. All database operations will be bundled within one transaction.
Here com a full configuration example for this database table for an entity we called - of course - simply "text".
Some comments before.
The selects (for="children" and for="identifier") are simple and nearly identical except for the WHERE clause to match either by identifier or by parent identifier.
Deleting is also easy. It will be done one by one. You cannot specify a big SQL statement deleting all texts of a list of texts in one action.
Setter method are defined as "upsert". The SQL syntax for UPSERT varies a lot between databases vendors. Here we use MYSQL style (INSERT INTO ... ON DUPLICATE KEY UPDATE ...). This way the upsert statement is also easy to create.
Note the mapping for "identifier" for the upsert query. This mapping will be executed after the upsert. The special property "SCOPE_IDENTITY()" will be filled with the new id created by the database in case the item found not found and it is actually an insert and not an update. Users of MYSQL know this as LAST_INSERT_ID.
<entity name="text">
<!-- === SELECT === -->
<query for="children">
<command type="sql">
SELECT
id AS identifier,
ctry AS connector_country,
lang AS connector_language,
value AS text
FROM
textdata
WHERE
key = :connectorEntity_name
AND
pid = :id
</command>
</query>
<query for="identifier">
<command type="sql">
SELECT
id AS identifier,
ctry AS connector_country,
lang AS connector_language,
value AS text
FROM
textdata
WHERE
key = :connectorEntity_name
AND
id = :id
</command>
</query>
<!-- === DELETE === -->
<query for="delete">
<command type="sql">
DELETE FROM
textdata
WHERE
id = :id
</command>
</query>
<!-- === UPSERT === -->
<query for="upsert">
<command type="sql">
INSERT INTO textdata
(id, key, pid, ctry, lang, value)
VALUES
(:text_identifier, :connectorEntity_name, :text_bucketId,
:connector_country, :connector_language, :text_text)
ON DUPLICATE KEY UPDATE
key = :connectorEntity_name,
pid = :text_bucketId,
ctry = :connector_country,
lang = :connector_language,
value = :text_text
</command>
<mappings>
<mapping for="identifier">
<field-path>SCOPE_IDENTITY()</field-path>
</mapping>
</mappings>
</query>
</entity>
8.8.2 Configuration Example: Text Data with Metadata
Now let us expand the previous example to show how we can handle subordinate data. Subordinate data could be subKeyValues or a keyValue, contentBuckets of a cord, mediaObjects of a mediaAsset and of course metaData of any entitydata item.
Suppose we store additional properties for each textdata record in a 1:n relationship.
The database table for text properties is defined as such:
-- MYSQL example for a simple table containing additional properties of a text
CREATE TABLE textprop (
id INT AUTOINCREMENT PRIMARY KEY,
pid INT,
name VARCHAR(60),
content VARCHAR(4000)
)
"pid" will contain the id of a textdata record.
We did not define any FOREIGN KEY constraint and no ON DELETE or ON UPDATE actions. That mean we have to do this stuff in the connector configuration manually.
Here com a full configuration example for this two database table for the entity called "text".
Some comment in advance:
- For the select queries metaData mappings have been added, to read associated textprop records into the metaData field of the resulting entitydata Text.
- We now have two delete queries. The first deleting the metaData (text props) of a textdata record. The second deleting the text itself.
- We also have two upsert queries. The first deleting the metaData (text props) of a textdata record.The second updating/inserting the text record and creating new text props through a metaData mapping. The command within the metaData mapping will be executed for each metaData value within the entitydata text.
- Within the upsert metaData mapping the metaData values can be rad from text context as subordinate elements. This elements are named as
<parentEntityType>_<childEntityType>_fieldname, e.g.text_keyvalue_keyLabel(metaData are actually of typ keyvalue). .
<entity name="text">
<!-- === SELECT === -->
<query for="children">
<command type="sql">
SELECT
id AS identifier,
ctry AS country,
lang AS connector_language,
value AS text
FROM
textdata
WHERE
key = :connectorEntity_name
AND
pid = :id
</command>
<mappings>
<mapping for="metaData">
<command type="sql">
SELECT
id AS identifier,
name AS key,
content AS value
FROM
textprop
WHERE
pid = :id
</command>
</mapping>
</mappings>
</query>
<query for="identifier">
<command type="sql">
SELECT
id AS identifier,
ctry AS connector_country,
lang AS connector_language,
value AS text
FROM
textdata
WHERE
key = :connectorEntity_name
AND
id = :id
</command>
<mappings>
<mapping for="metaData">
<command type="sql">
SELECT
id AS identifier,
name AS key,
content AS value
FROM
textprop
WHERE
pid = :id
</command>
</mapping>
</mappings>
</query>
<!-- === DELETE === -->
<query for="delete">
<command type="sql">
DELETE FROM textprop WHERE pid = :id
</command>
<mappings />
</query>
<query for="delete">
<command type="sql">
DELETE FROM textdata WHERE id = :id
</command>
</query>
<!-- === UPSERT === -->
<query for="upsert">
<command type="sql">
DELETE FROM textprop WHERE pid = :text_identifier
</command>
</query>
<query for="upsert">
<command type="sql">
INSERT INTO "textdata"
(id, key, pid, ctry, lang, value)
VALUES
(:text_identifier, :connectorEntity_name, :text_bucketId,
:connector_country, :connector_language, :text_text)
ON DUPLICATE KEY UPDATE
key = :connectorEntity_name,
pid = :text_bucketId,
ctry = :connector_country,
lang = :connector_language,
value = :text_text
</command>
<mappings>
<mapping for="identifier">
<field-path>SCOPE_IDENTITY()</field-path>
</mapping>
<mapping for="metaData">
<command type="sql">
INSERT INTO textprop
(pid, name, content)
VALUES
(:text_identifier, :text_keyvalue_key, :text_keyvalue_value)
</command>
</mapping>
</mappings>
</query>
</entity>
8.8.3 Additional Hints
You can specify more than one query for each type. Queries will be executed in the defined order.
You can specify more than one command element on each mapping element in upsert queries.
You can also use stored procs in all commands.
If you use foreign keys it is recommended to make use of ON UPDATE and ON DELETE triggers. This is much safer and faster than configuring similar operations in the connector configuration,
9 Questions and Answers
9.1 Stored Procedures
Question: Can we use a stored procedure within the connector? Answer: Yes. You are just configuring SQL statements. If the stored procedure produces a record set as result, then it is fine.
9.2 Which databases can we connect to
Actually the questions was "Can we connect to DB2 System".
The answer is simple: You can connect to any database system that has stable JDBC driver support for JavaEE. The publishing server installation already includes drivers for Microsoft SQL Server, Oracle, and MySQL. Other drivers have to installed into the Glassfish. In most cases Installation is simple: Just copy the driver jar file (together with its dependencies) into domains/pubserver/lib folder; restart Glassfish. Please read the documentation of the JDBC driver you need and inform yourself about potential issues.
Out of the box (and tested by WERK II):
- Microsoft SQL Server,
- Oracle,
- MySQL
Other potentially relevant database system that need additional driver installation (not tested by WERK II): This list is not complete.
- DB2
- H2
- Informix
- JavaDB/Derby
- PostgreSQL
- SQLite
- Sybase
- ...
See list of drivers: http://www.oracle.com/technetwork/java/index-136695.html
9.3 How to configure TableData
Configuration of table data is supported although not recommended. Typically table rows and table cells will be configured via entity-ref in their parent entities.
10 Known Issues
- Direction not supported for corded buckets. In queries for corded buckets or cords of buckets only destination buckets are supported.